| Guia |

Valentin Barriere
|
|---|---|
| Áreas | Ciencia e Ingeniería de datos, Inteligencia artificial |
| Sub Áreas | Minería de datos, Visualización de datos, Aprendizaje de máquina, Procesamiento de lenguaje natural |
| Estado | Disponible |
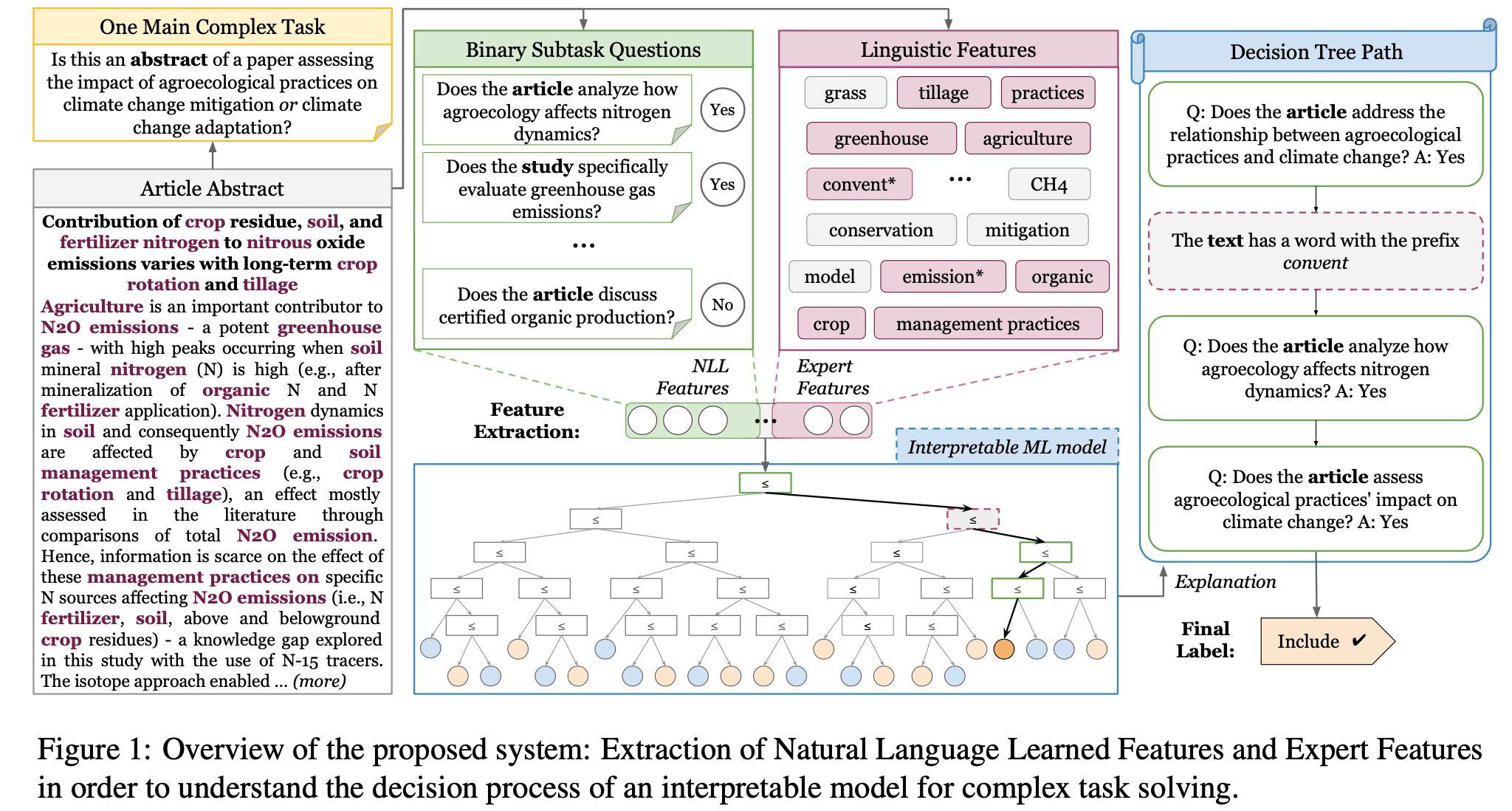
Content:
The growing use of artificial intelligence (AI) models, particularly deep learning, across diverse domains underscores their significant influence on crucial decision-making processes [2]. However, the inherent opacity of these models, often termed as "black boxes", raises concerns regarding their interpretability [3, 4]. This apprehension has spurred the development of Explainable AI (XAI), driven by the imperative to offer understandable insights into the workings of complex models [5], i.e. how the model arrives at the predictions. Within Natural Language Processing, old methods can rely on ad-hoc methods aiming to interpret a model [6, 7 However, interpretability relies on the possibility to know exactly why the model is making a prediction because they are inherent to the prediction and faithful to what the model actually computes. New methods rely on the self-explanation capacity of Large Language Models (LLM) like Chain-of-Thought [8, 9] which should be interpretable (because outputting explanations with their predictions) but have not always shown to give faithful explanations [10].
Driven by the necessity to reconcile the inherent opacity of black-box LLMs with the explainability characteristic of white-box models, like decision trees, our focus lies in harnessing the strengths of both paradigms. Our proposed strategy involves utilizing LLMs to break down a complex/difficult task to solve into a set of easier subtasks. These subtasks take the form of binary questions formulated in natural language, so they are easily interpretable. We then use the LLM zero-shot capacity to solve these subtasks, and transfer this capacity to a SLM (Small LM) to extract features that are interpretable (BERT-like, in our paper [1]), and that we can mixed with other linguistic interpretable features. Thereafter they are all used as inputs in a white-box interpretable model, such as decision trees, which offer transparent decision paths to elucidate the reasoning behind their predictions.
Task:
The goal of this thesis would be to improve the past method that we published (see in [1]). There are several axis of research:
- Improve the explainability part of the machine learning classifier
- Work on better subtask generation using in context question generation
- Work on an end-to-end approach in order to optimize the global loss
- Add hierarchical losses in order to integrate the task structure
Bibliography:
[1] Felipe Urrutia, Cristian Calderon, and Valentin Barriere. 2023. Deep Natural Language Feature Learning for Interpretable Prediction. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 3736–3763, Singapore. Association for Computational Linguistics.
[2] Dass, R. K., Petersen, N., Omori, M., Lave, T. R., & Visser, U. (2023). Detecting racial inequalities in criminal justice: towards an equitable deep learning approach for generating and interpreting racial categories using mugshots. AI & SOCIETY, 38(2), 897-918.
[3] Castelvecchi, D. (2016). Can we open the black box of AI?. Nature News, 538(7623), 20.
[4] Goodman, B., & Flaxman, S. (2017). European Union regulations on algorithmic decision-making and a “right to explanation”. AI magazine, 38(3), 50-57.
[5] Arrieta, A. B., Díaz-Rodríguez, N., Del Ser, J., Bennetot, A., Tabik, S., Barbado, A., ... & Herrera, F. (2020). Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Information fusion, 58, 82-115
[6] Ribeiro, M. T., Singh, S., & Guestrin, C. (2016, August). " Why should i trust you?" Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining (pp. 1135-1144).
[7] Fel, T., Ducoffe, M., Vigouroux, D., Cadène, R., Capelle, M., Nicodème, C., & Serre, T. (2023). Don't Lie to Me! Robust and Efficient Explainability with Verified Perturbation Analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 16153-16163).
[8] Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., ... & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35, 24824-24837.
[9] Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., ... & Zhou, D. (2022). Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171.
[10] A. Radhakrishnan et al., “Question Decomposition Improves the Faithfulness of Model-Generated Reasoning,” 2023.